CHARM++ and NAMD¶
NAMD is a computer software for classical molecular dynamics simulation, written using the Charm++ parallel programming model. It is noted for its parallel efficiency and is often used to simulate large systems (millions of atoms). It has been developed by the collaboration of the Theoretical and Computational Biophysics Group (TCB) and the Parallel Programming Laboratory (PPL) at the University of Illinois at Urbana–Champaign.
The purpose of this document is to show how Charm++ and NAMD were compiled on Thorny Flat, a cluster build from Skylake CPUs. The current stable sources 2.13 fail compilation using OFI network library. For that reason we will be using the Nightly archived sources available on the official NAMD site.
The sources can be downloaded for the most recent date at the moment of download. The sources can be download using this command:
VERSION=2021-10-05
wget https://www.ks.uiuc.edu/Research/namd/cvs/download/741376/NAMD_Git-${VERSION}_Source.tar.gz
This is the current Nightly build by the time of writing this document (2020-01-02). The nightly build can be downloaded from the browser on https://www.ks.uiuc.edu/Development/Download/download.cgi?PackageName=NAMD
The sources are archived in a tar and compressed file. Untar and uncompress them. Go into the created folder and untar the charm sources too:
tar -zxvf NAMD_Git-${VERSION}_Source.tar.gz
cd NAMD_Git-${VERSION}_Source/
tar -xvf charm-6.10.2.tar
We will compile Charm and NAMD using the Intel Compilers 2021, the latest version at the moment of writing this document:
module purge
module load compiler/2021.2.0 mkl/2021.2.0 mpi/2021.2.0
Compiling Charm++¶
We start compiling charm++, go into the charm-6.10.2 folder:
cd charm-6.10.2
We will compile 4 versions. The MPI version and the OFI version for both single threaded and shared memory versions:
MPICXX=mpiicpc ./build charm++ mpi-linux-x86_64 mpicxx ifort -j12 --with-production
MPICXX=mpiicpc ./build charm++ mpi-linux-x86_64 mpicxx ifort smp -j12 --with-production
./build charm++ ofi-linux-x86_64 icc ifort -j12 --with-production
./build charm++ ofi-linux-x86_64 icc ifort smp -j12 --with-production
Executing those 4 commands will compile charm++ in a variety of ways that take
advantage of Intel Omni-Path. The smp version takes one extra thread for managing communication reducing the amount of usable cores but allows to share memory efficiently allowing for computations with larger systems. That is why having the smp and non-smp versions is recommended.
You can test those 4 compilations of charm++ with the testsuite provided with the sources. Notice that before each new tests the previous binaries must be deleted. The following commands will perform the 4 tests suite runs:
cd mpi-linux-x86_64-ifort-mpicxx/tests/charm++
make clean && make && make test
cd ../../..
cd mpi-linux-x86_64-ifort-smp-mpicxx/tests/charm++
make clean && make && make test
cd ../../..
cd ofi-linux-x86_64-ifort-smp-icc/tests/charm++
make clean && make && make test
cd ../../..
cd ofi-linux-x86_64-ifort-icc/tests/charm++
make clean && make && make test
cd ../../..
cd ofi-linux-x86_64-ifort-smp-icc/tests/charm++
make clean && make
cd megatest && make && make test
cd ../../../..
The last case is a bit different as one test fail with smp. We should now return to the NAMD sources to continue the compilation:
cd ..
Compiling NAMD2¶
Now we proceed to compile NAMD. Download and install TCL and FFTW libraries asuming that you are now on the root folder for NAMD sources:
wget http://www.ks.uiuc.edu/Research/namd/libraries/fftw-linux-x86_64.tar.gz
tar xzf fftw-linux-x86_64.tar.gz
mv linux-x86_64 fftw
wget http://www.ks.uiuc.edu/Research/namd/libraries/tcl8.5.9-linux-x86_64.tar.gz
wget http://www.ks.uiuc.edu/Research/namd/libraries/tcl8.5.9-linux-x86_64-threaded.tar.gz
tar xzf tcl8.5.9-linux-x86_64.tar.gz
tar xzf tcl8.5.9-linux-x86_64-threaded.tar.gz
mv tcl8.5.9-linux-x86_64 tcl
mv tcl8.5.9-linux-x86_64-threaded tcl-threaded
The next step is to edit the file Make.charm to edit the variable CHARMBASE. Another option is to create a symbolic link called charm pointing to the location of the charm sources, like this:
ln -s charm-6.10.2 charm
The configuration of NAMD is done via a text file located at the arch folder. Create the following files with the commands:
cat << EOF > arch/Linux-x86_64-mpi-mpicxx.arch
NAMD_ARCH = Linux-x86_64
CHARMARCH = mpi-linux-x86_64-ifort-mpicxx
FLOATOPTS = -ip -axSKYLAKE-AVX512,CASCADELAKE -qopenmp-simd
CXX = icpc -std=c++11
CXXOPTS = -O2 \$(FLOATOPTS)
CXXNOALIASOPTS = -O2 -fno-alias \$(FLOATOPTS)
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -O2 \$(FLOATOPTS)
EOF
cat << EOF > arch/Linux-x86_64-mpi-smp-mpicxx.arch
NAMD_ARCH = Linux-x86_64
CHARMARCH = mpi-linux-x86_64-ifort-smp-mpicxx
FLOATOPTS = -ip -axSKYLAKE-AVX512,CASCADELAKE -qopenmp-simd
CXX = icpc -std=c++11
CXXOPTS = -O2 \$(FLOATOPTS)
CXXNOALIASOPTS = -O2 -fno-alias \$(FLOATOPTS)
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -O2 \$(FLOATOPTS)
EOF
cat << EOF > arch/Linux-x86_64-ofi-icc.arch
NAMD_ARCH = Linux-x86_64
CHARMARCH = ofi-linux-x86_64-ifort-icc
FLOATOPTS = -ip -axSKYLAKE-AVX512,CASCADELAKE -qopenmp-simd
CXX = icpc -std=c++11
CXXOPTS = -O2 \$(FLOATOPTS)
CXXNOALIASOPTS = -O2 -fno-alias \$(FLOATOPTS)
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -O2 \$(FLOATOPTS)
EOF
cat << EOF > arch/Linux-x86_64-ofi-smp-icc.arch
NAMD_ARCH = Linux-x86_64
CHARMARCH = ofi-linux-x86_64-ifort-smp-icc
FLOATOPTS = -ip -axSKYLAKE-AVX512,CASCADELAKE -qopenmp-simd
CXX = icpc -std=c++11
CXXOPTS = -O2 \$(FLOATOPTS)
CXXNOALIASOPTS = -O2 -fno-alias \$(FLOATOPTS)
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -O2 \$(FLOATOPTS)
EOF
Executing the code above will produce 4 files with the following contents.
File Linux-x86_64-mpi-mpicxx.arch:
NAMD_ARCH = Linux-x86_64
CHARMARCH = mpi-linux-x86_64-ifort-mpicxx
FLOATOPTS = -ip -axSKYLAKE-AVX512,CASCADELAKE -qopenmp-simd
CXX = icpc -std=c++11
CXXOPTS = -O2 $(FLOATOPTS)
CXXNOALIASOPTS = -O2 -fno-alias $(FLOATOPTS)
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -O2 $(FLOATOPTS)
File Linux-x86_64-mpi-smp-mpicxx.arch:
NAMD_ARCH = Linux-x86_64
CHARMARCH = mpi-linux-x86_64-ifort-smp-mpicxx
FLOATOPTS = -ip -axSKYLAKE-AVX512,CASCADELAKE -qopenmp-simd
CXX = icpc -std=c++11
CXXOPTS = -O2 $(FLOATOPTS)
CXXNOALIASOPTS = -O2 -fno-alias $(FLOATOPTS)
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -O2 $(FLOATOPTS)
File Linux-x86_64-ofi-icc.arch:
NAMD_ARCH = Linux-x86_64
CHARMARCH = ofi-linux-x86_64-ifort-icc
FLOATOPTS = -ip -axSKYLAKE-AVX512,CASCADELAKE -qopenmp-simd
CXX = icpc -std=c++11
CXXOPTS = -O2 $(FLOATOPTS)
CXXNOALIASOPTS = -O2 -fno-alias $(FLOATOPTS)
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -O2 $(FLOATOPTS)
File Linux-x86_64-ofi-smp-icc.arch:
NAMD_ARCH = Linux-x86_64
CHARMARCH = ofi-linux-x86_64-ifort-smp-icc
FLOATOPTS = -ip -axSKYLAKE-AVX512,CASCADELAKE -qopenmp-simd
CXX = icpc -std=c++11
CXXOPTS = -O2 $(FLOATOPTS)
CXXNOALIASOPTS = -O2 -fno-alias $(FLOATOPTS)
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -O2 $(FLOATOPTS)
To compile NAMD, the corresponding building folder must be created via the config command. The following commands will create 4 folders for the corresponding versions of charm++ that we will use:
./config Linux-x86_64-mpi-mpicxx --charm-arch mpi-linux-x86_64-ifort-mpicxx
./config Linux-x86_64-mpi-smp-mpicxx --charm-arch mpi-linux-x86_64-ifort-smp-mpicxx
./config Linux-x86_64-ofi-icc --charm-arch ofi-linux-x86_64-ifort-icc
./config Linux-x86_64-ofi-smp-icc --charm-arch ofi-linux-x86_64-ifort-smp-icc
Now we can go inside each folder and compile the code with make. To speed up the compilation, 12 execution lines will be used:
cd Linux-x86_64-mpi-mpicxx
make -j12
cd ..
cd Linux-x86_64-mpi-smp-mpicxx
make -j12
cd ..
cd Linux-x86_64-ofi-icc
make -j12
cd ..
cd Linux-x86_64-ofi-smp-icc
make -j12
cd ..
At the end of those compilations we will have 4 versions of the command namd2. However, due to a bug on Intel’s opa-psm2 the NAMD binaries will return an error when executed. The error looks similar to this:
hfi_userinit: mmap of status page (dabbad0008030000) failed: Operation not permitted
For the particular case of Thorny, executing NAMD will return (MPI version):
trcis001.hpc.wvu.edu.26685hfi_userinit: mmap of status page (dabbad00080b0000) failed: Operation not permitted
trcis001.hpc.wvu.edu.26685hfp_gen1_context_open: hfi_userinit: failed, trying again (1/3)
trcis001.hpc.wvu.edu.26685hfi_userinit: assign_context command failed: Invalid argument
trcis001.hpc.wvu.edu.26685hfp_gen1_context_open: hfi_userinit: failed, trying again (2/3)
trcis001.hpc.wvu.edu.26685hfi_userinit: assign_context command failed: Invalid argument
trcis001.hpc.wvu.edu.26685hfp_gen1_context_open: hfi_userinit: failed, trying again (3/3)
trcis001.hpc.wvu.edu.26685hfi_userinit: assign_context command failed: Invalid argument
trcis001.hpc.wvu.edu.26685PSM2 can't open hfi unit: -1 (err=23)
Abort(1615759) on node 0 (rank 0 in comm 0): Fatal error in PMPI_Init_thread: Other MPI error, error stack:
MPIR_Init_thread(703)........:
MPID_Init(923)...............:
MPIDI_OFI_mpi_init_hook(1211):
create_endpoint(1892)........: OFI endpoint open failed (ofi_init.c:1892:create_endpoint:Invalid argument)
Or (OFI version):
Charm++>ofi> provider: psm2
Charm++>ofi> control progress: 2
Charm++>ofi> data progress: 2
Charm++>ofi> maximum inject message size: 64
Charm++>ofi> eager maximum message size: 65536 (maximum header size: 40)
Charm++>ofi> cq entries count: 8
Charm++>ofi> use inject: 1
Charm++>ofi> maximum rma size: 4294967295
Charm++>ofi> mr mode: 0x1
Charm++>ofi> use memory pool: 0
trcis001.hpc.wvu.edu.26858hfi_userinit: mmap of status page (dabbad00080b0000) failed: Operation not permitted
trcis001.hpc.wvu.edu.26858hfp_gen1_context_open: hfi_userinit: failed, trying again (1/3)
trcis001.hpc.wvu.edu.26858hfi_userinit: assign_context command failed: Invalid argument
trcis001.hpc.wvu.edu.26858hfp_gen1_context_open: hfi_userinit: failed, trying again (2/3)
trcis001.hpc.wvu.edu.26858hfi_userinit: assign_context command failed: Invalid argument
trcis001.hpc.wvu.edu.26858hfp_gen1_context_open: hfi_userinit: failed, trying again (3/3)
trcis001.hpc.wvu.edu.26858hfi_userinit: assign_context command failed: Invalid argument
trcis001.hpc.wvu.edu.26858PSM2 can't open hfi unit: -1 (err=23)
------- Partition 0 Processor 0 Exiting: Called CmiAbort ------
Reason: OFI::LrtsInit::fi_endpoint error
[0] Stack Traceback:
[0:0] namd2 0x1126347 CmiAbortHelper(char const*, char const*, char const*, int, int)
[0:1] namd2 0x11262e7 CmiAbort
[0:2] namd2 0x1125088 LrtsInit(int*, char***, int*, int*)
[0:3] namd2 0x112664a ConverseInit
[0:4] namd2 0x68e302 BackEnd::init(int, char**)
[0:5] namd2 0x68332c main
[0:6] libc.so.6 0x7fbe439b53d5 __libc_start_main
[0:7] namd2 0x5d9ab9
The issue is related to the execute bit being set in the GNU_STACK of the ELF headers in a binary. That in turn attempts to map the memory region with both the read and execute bits enabled, rather than just the read bit as PSM2 is requesting. As described in this post:
https://stackoverflow.com/questions/32730643/why-in-mmap-prot-read-equals-prot-exec
And the solution was posted here:
https://github.com/intel/opa-psm2/issues/29
One can inspect a binary for this setting using readelf:
readelf --program-headers ./namd2
The output from that command will show this for the GNU_STACK:
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RWE 10
This issue can be fixed over the binaries already created by executing:
execstack -c ./namd2
From the NAMD source folder the following command will fix that for the 4 binaries:
execstack -c Linux-x86_64-*/namd2
Quick test NAMD2 for Alanin¶
Now we can start testing the 4 binaries of namd2.
NAMD offers a very small case for testing on src/alanin.
Execute NAMD on each folder to test the binary.
Notice that for the SMP binaries a couple of extra arguments are needed:
cd Linux-x86_64-mpi-mpicxx
./charmrun ++local +p2 ./namd2 src/alanin
cd ..
cd Linux-x86_64-ofi-icc
./charmrun ++local +p2 ./namd2 src/alanin
cd ..
cd Linux-x86_64-mpi-smp-mpicxx
./charmrun ++local +p2 ./namd2 src/alanin ++ppn2 +setcpuaffinity
cd ..
cd Linux-x86_64-ofi-smp-icc
./charmrun ++local +p2 ./namd2 src/alanin ++ppn2 +setcpuaffinity
cd ..
The MPI-based non-SMP binary is executed as follows:
$ ./charmrun ++local +p2 ./namd2 src/alanin
Running on 2 processors: ./namd2 src/alanin
charmrun> /bin/setarch x86_64 -R mpirun -np 2 ./namd2 src/alanin
Charm++> Running on MPI version: 3.1
Charm++> level of thread support used: MPI_THREAD_SINGLE (desired: MPI_THREAD_SINGLE)
Charm++> Running in non-SMP mode: 2 processes (PEs)
Charm++> Using recursive bisection (scheme 3) for topology aware partitions
Converse/Charm++ Commit ID: v6.10.2-0-g7bf00fa-namd-charm-6.10.2-build-2020-Aug-05-556
CharmLB> Load balancer assumes all CPUs are same.
Charm++> Running on 1 hosts (2 sockets x 12 cores x 2 PUs = 48-way SMP)
Charm++> cpu topology info is gathered in 0.001 seconds.
Info: NAMD Git-2021-10-05 for Linux-x86_64-MPI
...
The OFI non-SMP binaries can be tested in a similar way:
$ ./charmrun ++local +p2 ./namd2 src/alanin
Running on 2 processors: ./namd2 src/alanin
charmrun> /bin/setarch x86_64 -R mpirun -np 2 ./namd2 src/alanin
Charm++>ofi> provider: psm2
Charm++>ofi> control progress: 2
Charm++>ofi> data progress: 2
Charm++>ofi> maximum inject message size: 64
Charm++>ofi> eager maximum message size: 65536 (maximum header size: 40)
Charm++>ofi> cq entries count: 8
Charm++>ofi> use inject: 1
Charm++>ofi> maximum rma size: 4294963200
Charm++>ofi> mr mode: 0x1
Charm++>ofi> use memory pool: 0
Charm++>ofi> use request cache: 0
Charm++>ofi> number of pre-allocated recvs: 8
Charm++>ofi> exchanging addresses over OFI
Charm++> Running in non-SMP mode: 2 processes (PEs)
Charm++> Using recursive bisection (scheme 3) for topology aware partitions
Converse/Charm++ Commit ID: v6.10.2-0-g7bf00fa-namd-charm-6.10.2-build-2020-Aug-05-556
CharmLB> Load balancer assumes all CPUs are same.
Charm++> Running on 1 hosts (2 sockets x 12 cores x 2 PUs = 48-way SMP)
Charm++> cpu topology info is gathered in 0.001 seconds.
Info: NAMD Git-2021-10-05 for Linux-x86_64-ofi
...
The SMP binaries are special in the arguments needed to run.
The binary at Linux-x86_64-mpi-smp-mpicxx needs at least an extra argument ++ppn:
$ ./charmrun ++local +p2 ./namd2 src/alanin ++ppn2
Running on 1 processors: ./namd2 src/alanin ++ppn2
charmrun> /bin/setarch x86_64 -R mpirun -np 1 ./namd2 src/alanin ++ppn2
Charm++> Running on MPI version: 3.1
Charm++> level of thread support used: MPI_THREAD_FUNNELED (desired: MPI_THREAD_FUNNELED)
Charm++> Running in SMP mode: 1 processes, 2 worker threads (PEs) + 1 comm threads per process, 2 PEs total
Charm++> The comm. thread both sends and receives messages
Charm++> Using recursive bisection (scheme 3) for topology aware partitions
Converse/Charm++ Commit ID: v6.10.2-0-g7bf00fa-namd-charm-6.10.2-build-2020-Aug-05-556
Charm++ communication thread will sleep due to single-process run.
CharmLB> Load balancer assumes all CPUs are same.
Charm++> Running on 1 hosts (2 sockets x 12 cores x 2 PUs = 48-way SMP)
Charm++> cpu topology info is gathered in 0.001 seconds.
Info: NAMD Git-2021-10-05 for Linux-x86_64-MPI-smp
...
The OFI SMP binaries Linux-x86_64-ofi-smp-icc needs +setcpuaffinity because at least one thread for communication and that will oversubscribe the number of worker processes plus one communication thread:
$ ./charmrun ++local +p2 ./namd2 src/alanin ++ppn2 +setcpuaffinity
Running on 1 processors: ./namd2 src/alanin ++ppn2 +setcpuaffinity
charmrun> /bin/setarch x86_64 -R mpirun -np 1 ./namd2 src/alanin ++ppn2 +setcpuaffinity
Charm++>ofi> provider: psm2
Charm++>ofi> control progress: 2
Charm++>ofi> data progress: 2
Charm++>ofi> maximum inject message size: 64
Charm++>ofi> eager maximum message size: 65536 (maximum header size: 40)
Charm++>ofi> cq entries count: 8
Charm++>ofi> use inject: 1
Charm++>ofi> maximum rma size: 4294963200
Charm++>ofi> mr mode: 0x1
Charm++>ofi> use memory pool: 0
Charm++>ofi> use request cache: 0
Charm++>ofi> number of pre-allocated recvs: 8
Charm++>ofi> exchanging addresses over OFI
Charm++> Running in SMP mode: 1 processes, 2 worker threads (PEs) + 1 comm threads per process, 2 PEs total
Charm++> The comm. thread both sends and receives messages
Charm++> Using recursive bisection (scheme 3) for topology aware partitions
Converse/Charm++ Commit ID: v6.10.2-0-g7bf00fa-namd-charm-6.10.2-build-2020-Aug-05-556
Charm++ communication thread will sleep due to single-process run.
CharmLB> Load balancer assumes all CPUs are same.
Charm++> cpu affinity enabled.
Charm++> Running on 1 hosts (2 sockets x 12 cores x 2 PUs = 48-way SMP)
Charm++> cpu topology info is gathered in 0.013 seconds.
Info: NAMD Git-2021-10-05 for Linux-x86_64-ofi-smp
...
The extra argument is needed as multiple PEs get assigned to same core. Setting +setcpuaffinity will prevent that.
You should not pay much attention to timings for this case. The purpose of the executions above is to proof than NAMD works at least for a simple execution. The memory used start showing important changes between the 4 binaries:
11:52:06-build@trcis001:/shared/src/NAMD_Git-2021-10-05_Source/Linux-x86_64-mpi-mpicxx$
WallClock: 0.018382 CPUTime: 0.018382 Memory: 4145.171875 MB
11:52:20-build@trcis001:/shared/src/NAMD_Git-2021-10-05_Source/Linux-x86_64-ofi-icc$
WallClock: 0.019521 CPUTime: 0.016802 Memory: 318.988281 MB
11:52:11-build@trcis001:/shared/src/NAMD_Git-2021-10-05_Source/Linux-x86_64-mpi-smp-mpicxx$
WallClock: 0.019347 CPUTime: 0.015666 Memory: 2610.667969 MB
11:52:01-build@trcis001:/shared/src/NAMD_Git-2021-10-05_Source/Linux-x86_64-ofi-smp-icc$
WallClock: 0.064102 CPUTime: 0.028695 Memory: 458.476562 MB
The OFI binaries use less memory than the MPI versions. The SMP versions use less memory than the non-SMP versions but the difference is lower compared with the OFI vs MPI binaries.
Script summarizing compilation of NAMD¶
The next script execute all steps above:
#!/bin/bash
VERSION=2021-10-06
if [ ! -f NAMD_Git-${VERSION}_Source.tar.gz ]
then
wget https://www.ks.uiuc.edu/Research/namd/cvs/download/741376/NAMD_Git-${VERSION}_Source.tar.gz
fi
if [ ! -d NAMD_Git-${VERSION}_Source ]
then
tar -zxvf NAMD_Git-${VERSION}_Source.tar.gz
fi
cd NAMD_Git-${VERSION}_Source/
if [ ! -d charm-6.10.2 ]
then
tar -xvf charm-6.10.2.tar
fi
cd charm-6.10.2
MPICXX=mpiicpc ./build charm++ mpi-linux-x86_64 mpicxx ifort -j12 --with-production
MPICXX=mpiicpc ./build charm++ mpi-linux-x86_64 mpicxx ifort smp -j12 --with-production
./build charm++ ofi-linux-x86_64 icc ifort -j12 --with-production
./build charm++ ofi-linux-x86_64 icc ifort smp -j12 --with-production
cd mpi-linux-x86_64-ifort-mpicxx/tests/charm++
make clean && make && cd megatest && make && make test
cd ../../../..
cd mpi-linux-x86_64-ifort-smp-mpicxx/tests/charm++
make clean && make && cd megatest && make && make test
cd ../../../..
cd ofi-linux-x86_64-ifort-smp-icc/tests/charm++
make clean && make && cd megatest && make && make test
cd ../../../..
cd ofi-linux-x86_64-ifort-icc/tests/charm++
make clean && make && cd megatest && make && make test
cd ../../../..
cd ofi-linux-x86_64-ifort-smp-icc/tests/charm++
make clean && make && cd megatest && make && make test
cd ../../../..
cd ..
wget http://www.ks.uiuc.edu/Research/namd/libraries/fftw-linux-x86_64.tar.gz
tar xzf fftw-linux-x86_64.tar.gz
mv linux-x86_64 fftw
wget http://www.ks.uiuc.edu/Research/namd/libraries/tcl8.5.9-linux-x86_64.tar.gz
wget http://www.ks.uiuc.edu/Research/namd/libraries/tcl8.5.9-linux-x86_64-threaded.tar.gz
tar xzf tcl8.5.9-linux-x86_64.tar.gz
tar xzf tcl8.5.9-linux-x86_64-threaded.tar.gz
mv tcl8.5.9-linux-x86_64 tcl
mv tcl8.5.9-linux-x86_64-threaded tcl-threaded
ln -s charm-6.10.2 charm
cat << EOF > arch/Linux-x86_64-mpi-mpicxx.arch
NAMD_ARCH = Linux-x86_64
CHARMARCH = mpi-linux-x86_64-ifort-mpicxx
FLOATOPTS = -ip -axSKYLAKE-AVX512,CASCADELAKE -qopenmp-simd
CXX = icpc -std=c++11
CXXOPTS = -O2 \$(FLOATOPTS)
CXXNOALIASOPTS = -O2 -fno-alias \$(FLOATOPTS)
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -O2 \$(FLOATOPTS)
EOF
cat << EOF > arch/Linux-x86_64-mpi-smp-mpicxx.arch
NAMD_ARCH = Linux-x86_64
CHARMARCH = mpi-linux-x86_64-ifort-smp-mpicxx
FLOATOPTS = -ip -axSKYLAKE-AVX512,CASCADELAKE -qopenmp-simd
CXX = icpc -std=c++11
CXXOPTS = -O2 \$(FLOATOPTS)
CXXNOALIASOPTS = -O2 -fno-alias \$(FLOATOPTS)
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -O2 \$(FLOATOPTS)
EOF
cat << EOF > arch/Linux-x86_64-ofi-icc.arch
NAMD_ARCH = Linux-x86_64
CHARMARCH = ofi-linux-x86_64-ifort-icc
FLOATOPTS = -ip -axSKYLAKE-AVX512,CASCADELAKE -qopenmp-simd
CXX = icpc -std=c++11
CXXOPTS = -O2 \$(FLOATOPTS)
CXXNOALIASOPTS = -O2 -fno-alias \$(FLOATOPTS)
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -O2 \$(FLOATOPTS)
EOF
cat << EOF > arch/Linux-x86_64-ofi-smp-icc.arch
NAMD_ARCH = Linux-x86_64
CHARMARCH = ofi-linux-x86_64-ifort-smp-icc
FLOATOPTS = -ip -axSKYLAKE-AVX512,CASCADELAKE -qopenmp-simd
CXX = icpc -std=c++11
CXXOPTS = -O2 \$(FLOATOPTS)
CXXNOALIASOPTS = -O2 -fno-alias \$(FLOATOPTS)
CXXCOLVAROPTS = -O2 -ip
CC = icc
COPTS = -O2 \$(FLOATOPTS)
EOF
./config Linux-x86_64-mpi-mpicxx --charm-arch mpi-linux-x86_64-ifort-mpicxx
./config Linux-x86_64-mpi-smp-mpicxx --charm-arch mpi-linux-x86_64-ifort-smp-mpicxx
./config Linux-x86_64-ofi-icc --charm-arch ofi-linux-x86_64-ifort-icc
./config Linux-x86_64-ofi-smp-icc --charm-arch ofi-linux-x86_64-ifort-smp-icc
cd Linux-x86_64-mpi-mpicxx
make -j12
cd ..
cd Linux-x86_64-mpi-smp-mpicxx
make -j12
cd ..
cd Linux-x86_64-ofi-icc
make -j12
cd ..
cd Linux-x86_64-ofi-smp-icc
make -j12
cd ..
execstack -c Linux-x86_64-*/namd2
cd Linux-x86_64-mpi-mpicxx
./charmrun ++local +p2 ./namd2 src/alanin
make release
cd ..
cd Linux-x86_64-mpi-smp-mpicxx
./charmrun ++local +p2 ./namd2 src/alanin ++ppn2
make release
cd ..
cd Linux-x86_64-ofi-icc
./charmrun ++local +p2 ./namd2 src/alanin
make release
cd ..
cd Linux-x86_64-ofi-smp-icc
./charmrun ++local +p2 ./namd2 src/alanin ++ppn2 +setcpuaffinity
make release
cd ..
Benchmarking NAMD2¶
NAMD has a case often used for Benchmarking. Still small but we can start extracting some performance figures. ApoA1 benchmark (92,224 atoms, periodic; 2fs timestep with rigid bonds, 12A cutoff with PME every 2 steps):
Download the code with:
wget http://www.ks.uiuc.edu/Research/namd/utilities/apoa1.tar.gz
tar xzf apoa1.tar.gz
Once you have untar the package. Edit the input file and change the line for the output. You can do that from the command line with:
cd apoa1
cp apoa1.namd apoa1.namd_BKP
cat apoa1.namd_BKP | sed 's/\/usr//g' > apoa1.namd
We start with a simple execution using 12 cores. Notice that the first time you execute NAMD it will compute the FFT optimization and that could take a several seconds. With 12 cores the simulation last for around a minute:
../Linux-x86_64-mpi-mpicxx/charmrun +p12 ../Linux-x86_64-mpi-mpicxx/namd2 apoa1.namd
../Linux-x86_64-mpi-mpicxx/charmrun +p12 ../Linux-x86_64-mpi-mpicxx/namd2 apoa1.namd
At the end of the second run the timing was:
WallClock: 32.377525 CPUTime: 32.377525 Memory: 2932.089844 MB
[Partition 0][Node 0] End of program
The second version with MPI and SMP is like this:
../Linux-x86_64-mpi-smp-mpicxx/charmrun +p12 ../Linux-x86_64-mpi-smp-mpicxx/namd2 apoa1.namd ++ppn2
../Linux-x86_64-mpi-smp-mpicxx/charmrun +p12 ../Linux-x86_64-mpi-smp-mpicxx/namd2 apoa1.namd ++ppn2
The timing for this version is similar:
WallClock: 29.577475 CPUTime: 29.438684 Memory: 2853.781250 MB
[Partition 0][Node 0] End of program
The OFI versions run like this:
../Linux-x86_64-ofi-icc/charmrun +p12 ../Linux-x86_64-ofi-icc/namd2 apoa1.namd
../Linux-x86_64-ofi-icc/charmrun +p12 ../Linux-x86_64-ofi-icc/namd2 apoa1.namd
With timings for the second run:
WallClock: 33.552193 CPUTime: 33.414692 Memory: 662.109375 MB
[Partition 0][Node 0] End of program
The final binary is OFI with SMP enabled:
../Linux-x86_64-ofi-smp-icc/charmrun +p12 ../Linux-x86_64-ofi-smp-icc/namd2 apoa1.namd ++ppn2
../Linux-x86_64-ofi-smp-icc/charmrun +p12 ../Linux-x86_64-ofi-smp-icc/namd2 apoa1.namd ++ppn2
With timings:
WallClock: 34.350666 CPUTime: 34.264492 Memory: 641.882812 MB
[Partition 0][Node 0] End of program
At this point all four binaries perform very similarly. However, this execution was done on the head node, where several user and system processes could be taking CPU time, making any claim about performance misleading.
Our next step is to move the execution to an isolated compute node where the time could be more accurate.
To do this lets request an interactive execution on an isolated node:
qsub -I -n -l nodes=1:ppn=40
Once you log into the compute node, load clean your modules and load the Intel Compilers 2021:
module purge
module load compiler/2021.2.0 mpi/2021.2.0 mkl/2021.2.0
The following script can be used to execute 4 versions of NAMD under the same conditions multiple times to gather a more precise timing.
The first execution will be larger due to NAMD computing the FFT parameter optimization.
The script could be called run_apoa1.sh:
#!/bin/bash
for j in 2 4 8 10 20 40
do
for i in 0 1 2 3
do
echo Linux-x86_64-mpi-mpicxx ${j} ${i}
../Linux-x86_64-mpi-mpicxx/charmrun +p$j \
../Linux-x86_64-mpi-mpicxx/namd2 apoa1.namd > mpi_${j}_${i}.dat
echo Linux-x86_64-mpi-smp-mpicxx ${j} ${i}
../Linux-x86_64-mpi-smp-mpicxx/charmrun +p$j \
../Linux-x86_64-mpi-smp-mpicxx/namd2 apoa1.namd ++ppn2 > mpi_smp_${j}_${i}.dat
echo Linux-x86_64-ofi-icc ${j} ${i}
../Linux-x86_64-ofi-icc/charmrun +p$j \
../Linux-x86_64-ofi-icc/namd2 apoa1.namd > ofi_${j}_${i}.dat
echo Linux-x86_64-ofi-smp-icc ${j} ${i}
../Linux-x86_64-ofi-smp-icc/charmrun +p$j \
../Linux-x86_64-ofi-smp-icc/namd2 apoa1.namd ++ppn2 +setcpuaffinity > ofi_smp_${j}_${i}.dat
done
done
The script can be executed like this:
./run_apoa1.sh
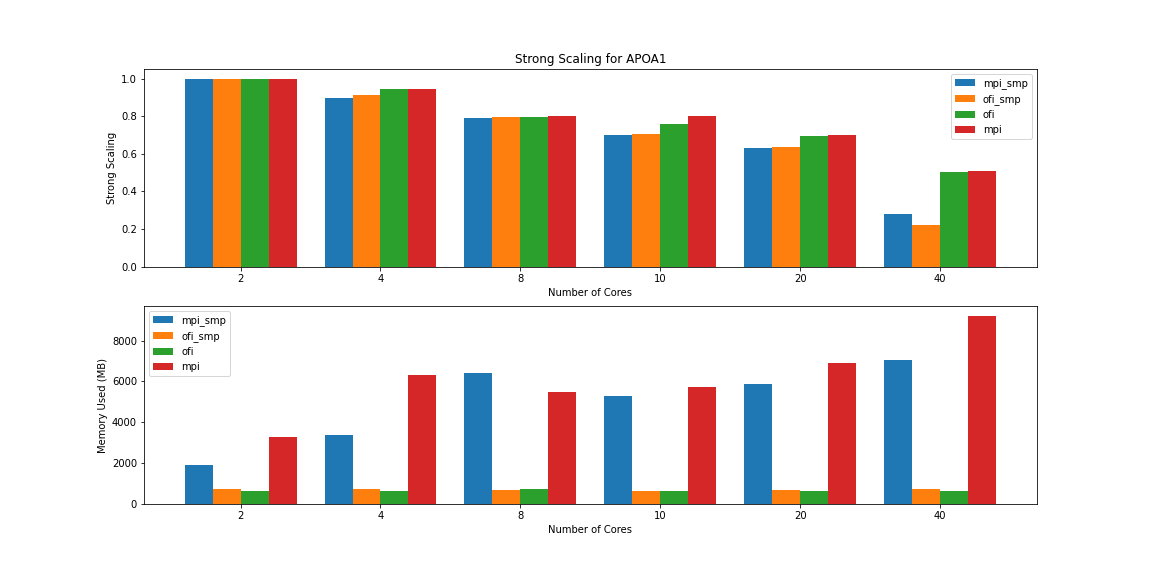
From the figure above we can see that the MPI versions consume more memory as we use more cores and the memory usage is larger compared with the OFI versions. For computing the strong scaling we use the timing for 2 cores as reference. The equation for strong scaling is t1/(tn*N) where t1 is the runtime for 1 core, tn is the time when N cores are used. Notice that there is an small advantage for the non-SMP versions (MPI and OFI) and with a high penalty for the 40 core case with scaling under 25%.
More significant for measuring the performance of NAMD for large systems comes from the STMV benchmark (1,066,628 atoms, periodic; 2fs timestep with rigid bonds, 12A cutoff with PME every 2 steps)
Download the input for the STMV benchmark, untar and uncompress the package and move into the folder:
wget https://www.ks.uiuc.edu/Research/namd/utilities/stmv.tar.gz
tar -zxvf stmv.tar.gz
cd stmv
The STMV execution takes longer so a submission script is better suited for the task. Our next set of tests will explore the best performance that we can get using all the cores on a single node. There are several options for the SMP case either adding more worker threads (+pN) or adding more PEs per logical node (++ppn N).
The first set of benchmark uses the SMP builds. Each node has 40 cores so there are several ways of balance the number of process and the number of threads on each process. The benchmarks below uses the 40 cores under a different number of computational threads and the complementary number of processes.
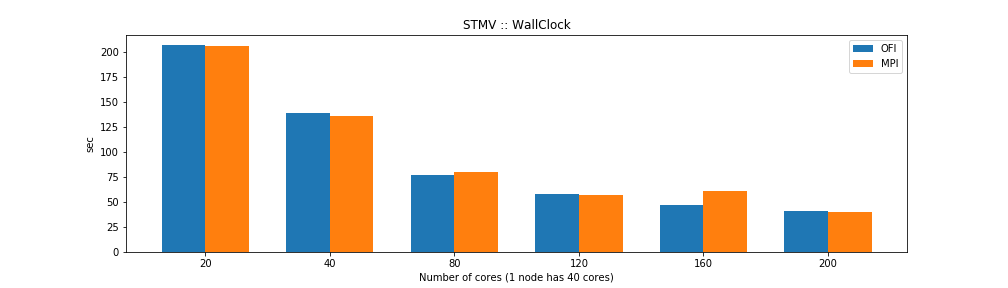
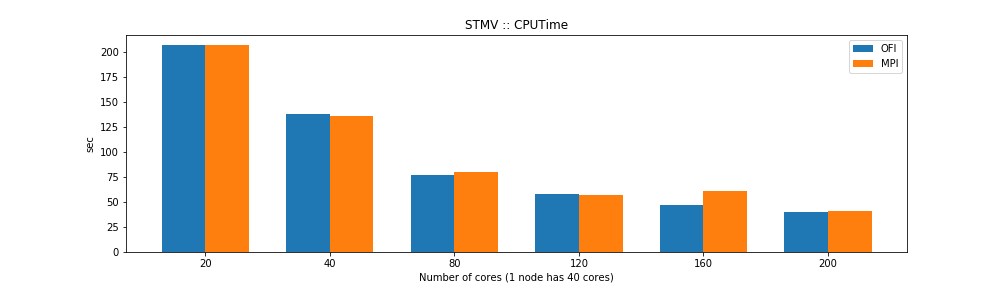
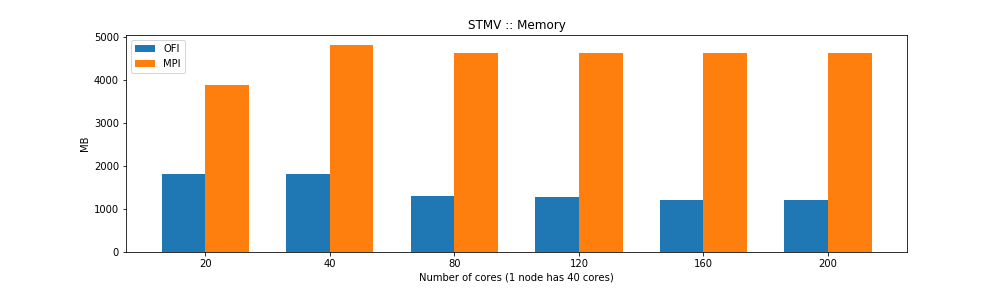
The results show that the MPI and OFI versions are similar in CPU time but differ in wall time. That could be explained by the OFI being more efficient network I/O improving the overall time the computer needs to perform the task. From the point of view of memory usage the OFI version shows considerably better memory usage.
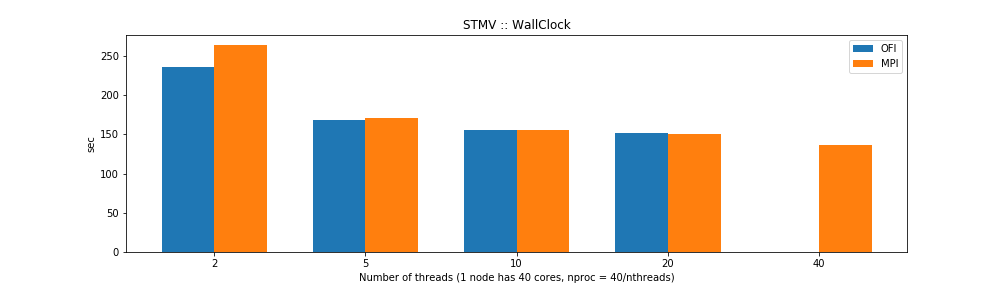
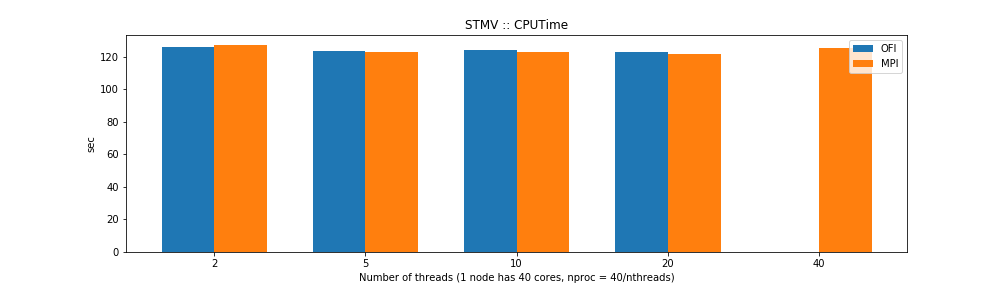
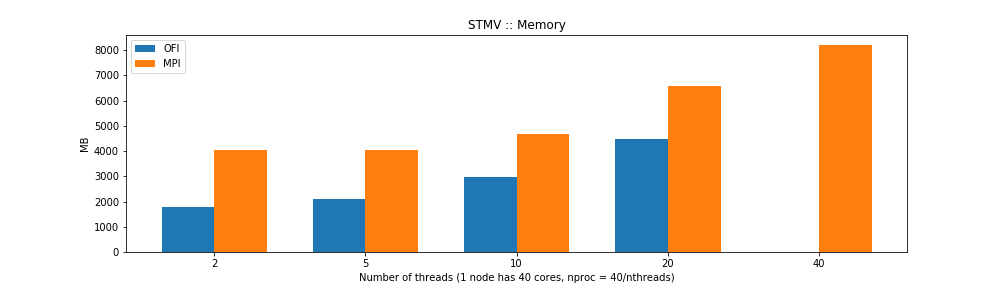
For the case of single thread NAMD builds the benchmarks show that the OFI and MPI flavors behave similar in terms of performance with an small advantage for OFI due to a better communication between nodes compared to the MPI build. The big advantage comes from the memory usage, the OFI build uses less than half memory compared to MPI build.
Conclusions¶
We have explore the performance of NAMD using two flavors of network communication both for single thread and SMP build. The benchmarks using STMV (1 million atoms) shows an small advantage for OFI in most cases. However, it it differentiate notably on its memory usage, something that could be critical for systems with large number of atoms.